4.1 DGLDataset 클래스¶
DGLDataset 는 dgl.data 에서 정의된 그래프 데이터셋을 프로세싱하고, 로딩하고 저장하기 위한 기본 클래스이다. 이는 그래프 데이트를 서치하는 기본 파이프라인을 구현한다. 아래 순서도는 파이프라인이 어떻게 동작하는지를 보여준다.
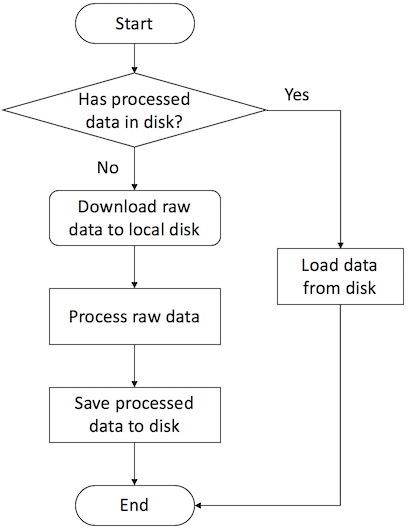
DGLDataset 클래스에 정의된 그래프 데이터 입력 파이프라인에 대한 순서도¶
원격 또는 로컬 디스크에 있는 그래프 데이터셋을 처리하기 위해서, dgl.data.DGLDataset 를 상속해서 클래스를 정의하나. 예로, MyDataset 이라고 하자. MyDataset 템플릿은 다음과 같다.
from dgl.data import DGLDataset
class MyDataset(DGLDataset):
""" Template for customizing graph datasets in DGL.
Parameters
----------
url : str
URL to download the raw dataset
raw_dir : str
Specifying the directory that will store the
downloaded data or the directory that
already stores the input data.
Default: ~/.dgl/
save_dir : str
Directory to save the processed dataset.
Default: the value of `raw_dir`
force_reload : bool
Whether to reload the dataset. Default: False
verbose : bool
Whether to print out progress information
"""
def __init__(self,
url=None,
raw_dir=None,
save_dir=None,
force_reload=False,
verbose=False):
super(MyDataset, self).__init__(name='dataset_name',
url=url,
raw_dir=raw_dir,
save_dir=save_dir,
force_reload=force_reload,
verbose=verbose)
def download(self):
# download raw data to local disk
pass
def process(self):
# process raw data to graphs, labels, splitting masks
pass
def __getitem__(self, idx):
# get one example by index
pass
def __len__(self):
# number of data examples
pass
def save(self):
# save processed data to directory `self.save_path`
pass
def load(self):
# load processed data from directory `self.save_path`
pass
def has_cache(self):
# check whether there are processed data in `self.save_path`
pass
DGLDataset 클래스에는 서브클래스에서 꼭 구현되어야 하는 함수들 process() ,
__getitem__(idx) 와 __len__() 이 있다. 또한 DGL은 저장과 로딩을 구현하는 것을 권장하는데, 그 이유는 큰 데이터셋 처리 시간을 많이 줄일 수 있고, 이를 쉽게 구현하는데 필요한 API들이 있기 때문이다. (4.4 데이터 저장과 로딩 참고)
DGLDataset 의 목적은 그래프 데이터 로드에 필요한 편리하고 표준적인 방법을 제공하는 것이다. 그래프, 피쳐, 레이블, 그리고 데이터셋에 대한 기본적인 정보 (클래스 개수, 레이블 개수 등)을 저장할 수 있다. 샘플링, 파티셔닝 또는 파쳐 normalization과 같은 작업은 DGLDataset 의 서브클래스 밖에서 수행된다.
이 장의 나머지에서는 파이프라인에서 함수를 구현하는 best practice들을 소개한다.